製品の概要について
社内の会計システムや、CRM、
チャネル毎のサブシステムなど、
様々なデータベースを
仮想的につなげて比較可能に。
DYNATREKが
お客様のDX推進を
加速します。

DX推進やカスタマーエクスペリエンスの向上、
経営ダッシュボード構築において欠かせない、
「企業内外のデータの統合と可視化・共有」を
即座に実現できる製品
DYNATREKができること、それは企業内で分断されてきたシステム毎のデータを、「経営・業務の目線」で仮想的に再編することです。
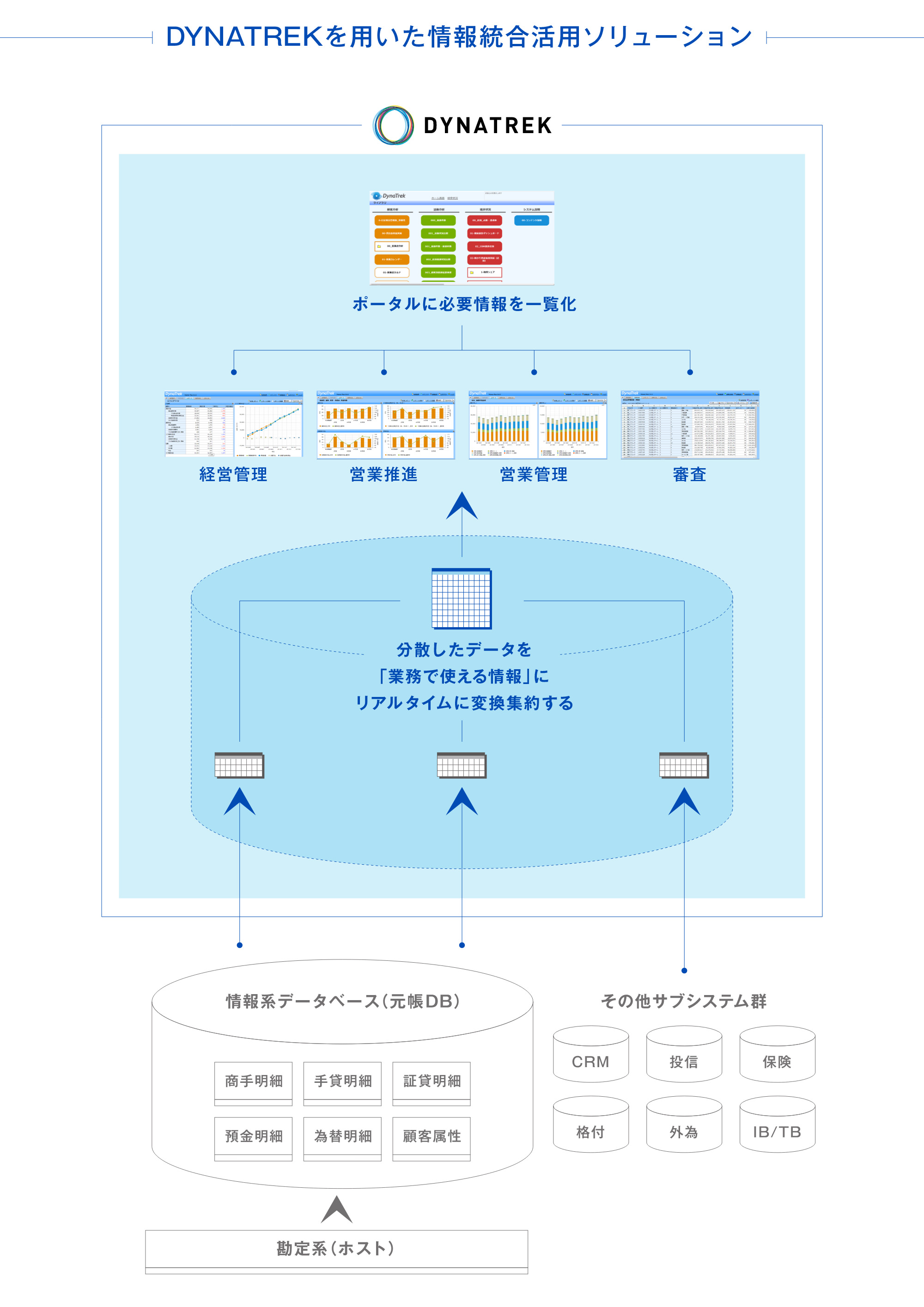
例えば、昨今DX推進で重視される「お客様との絶え間ない接点の創出」において、モバイルアプリ開発やAIの導入などが進んでいますが、この前提には「必要なデータを、ニーズに応じて柔軟に、かつタイムリーに取得できること」が必要です。
多くの企業、特に大組織においては、例えばCRM、コールセンター、受発注管理システムなどにデータが分散し、お客様との接点の全体像をタイムリーにとらえることが難しくなっています。
DYNATREKは、ユーザーの検索毎にこれらの様々なシステムを毎回横断的に検索し、あたかもそこに「全てが統合されたデータベース」が存在するかのように振る舞うことが可能です。
私たちは、DX推進やカスタマーエクスペリエンスの向上、経営ダッシュボード構築のプロジェクトを立ち上げたときに、「データ統合と集約」のために多くの時間が費やされ、肝心のコンテンツ開発になかなか着手できない、という光景をなくしたいと考えています。
DYNATREKを利用すれば、「何がみたくて、そのデータはどこにあるのか」さえわかれば、即座に必要なデータが共有され、本質的な価値を生み出すコンテンツ開発に注力することができます。
DYNATREKは金融機関、官公庁、通信会社、電力会社等で広く活用されており、特に金融機関においては、日本全国の約4割の地方銀行様において、全社で活用する分析基盤としてご活用いただいております。


なぜ、このような製品を当社はつくるのか
今も昔も変わらない、「データを流し込む」ことの大変さ
一般的に、データを統合するためには、「大きな箱に、データを流し込む」方法が一般的です。これは、オンプレミスでもクラウドでも、30年前から変わらない発想です。 ハードウエアの性能が向上し、クラウドサービスの可用性・セキュリティが向上した昨今、「大きな箱」に流し込みさえすれば、どのような大容量データでも問題なく取り扱える世の中になりました。
一方で、大組織において問題となるのが、「大きな箱を複数持っている」ケースです。
実は、昨今の技術革新においても、相変わらず大変でありつづけていることが、「データを流し込みつづける」仕組みの構築です。 「データを流し込む」仕組みは、1回限りであればコピーするだけですが、毎日流し込むとなると、障害が発生した時の対処を決めたり、データが溜まりすぎないように昔のデータを削除したり、様々な決まりをつくらなければなりません。
DX推進プロジェクトを行うとき、「何をやるか」の前段に、「どの箱に何をいれるのか」という議論がどうしても先行してしまうので、本当に重要な、「データをどのようにビジネスに活かすのか」という議論は、プロジェクトの後半に煮詰めることになってしまいます。
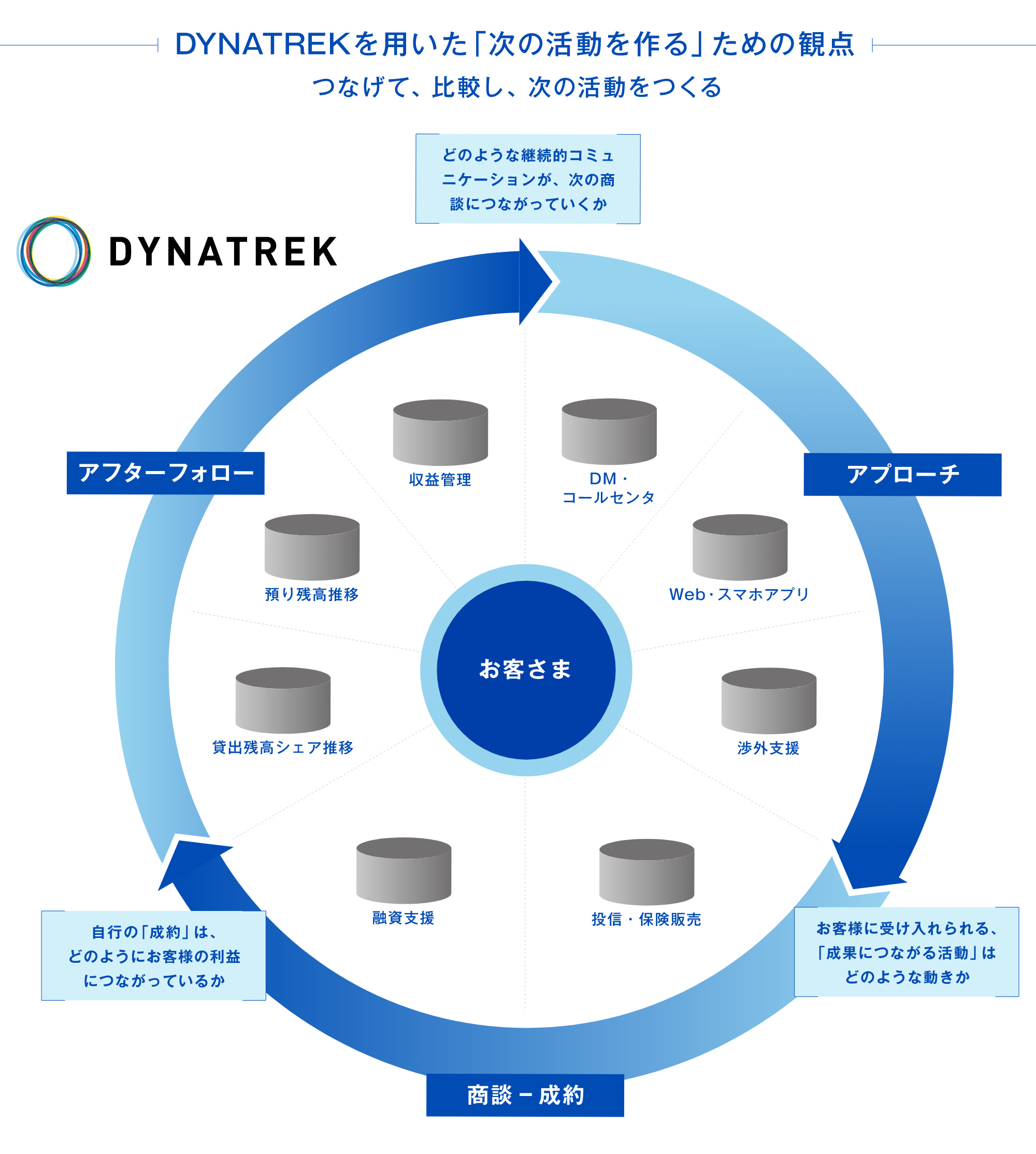
「何をみるか」の先に、「どのような動きをデザインしたいのか」がある
私たちは、データを活用するプロジェクトにおいて、「このデータを見て誰が何をするのか」という議論、つまり活動のデザインに最も時間が割かれるべきであり、ビジネスインパクトを決める要であると考えています。
そのため、DYNATREKは、見るべきデータが複数の箱にまたがっていたとしても、「もしこれが一つの箱に入っていたら・・」という姿を仮想的につくりだし、そしてそれがそのままシステムとして活用することができる仕組みになっています。
労力のかかる、「データをどう流し込むか」という議論に時間を割くことなく、「このプロジェクトでつくりだしたい動きは何なのか」ということを話し合い、そしてそこに向けて最善のインターフェースを作っていくことができます。
ビジネスによいインパクトを与えることができるデータ活用システムを考える中で、「仮想データベース」という方法論は、目的に対して最短距離をたどることができる方策でした。そして、当社はこの技術を30年来研究しつづけ、日本だけでなく米国やその他の国でも国際的な特許を取得しています。
DYNATREKの技術的なご説明
ユーザー層/データ辞書層/データ接続層の三層構造
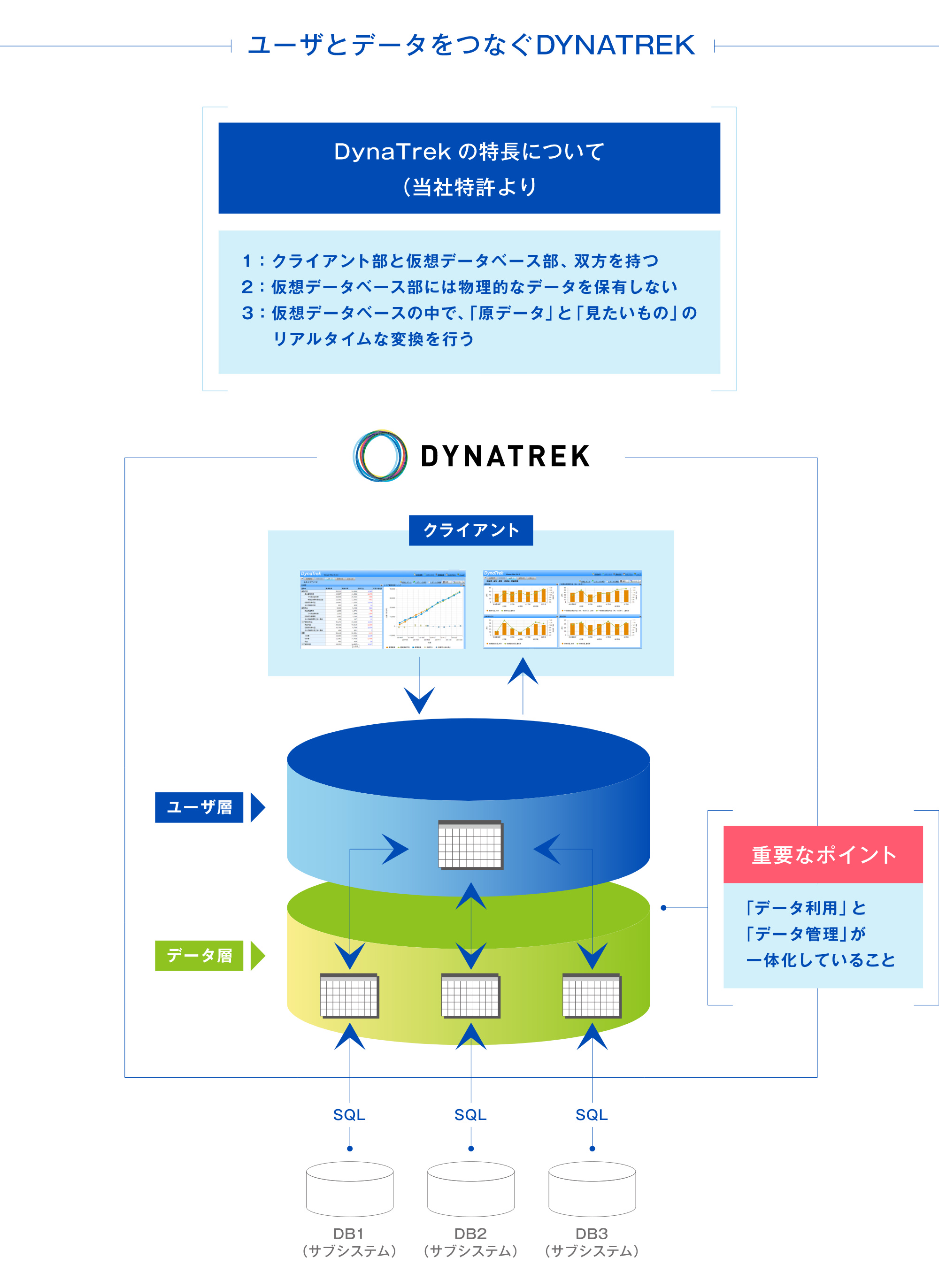
DYNATREKの特長は、「分析の知見を全社員で共有する」「集約したデータを分析する」「さまざまなシステムをつなぐ」の三要素が一つのツールで実現可能であることにあります。
ここでは、DYNATREKの三層構造について簡単にご紹介いたします。
ビジネスユーザーが直感的にわかる、データ構造を提供し、即座にコンテンツが作成できる環境を提供。
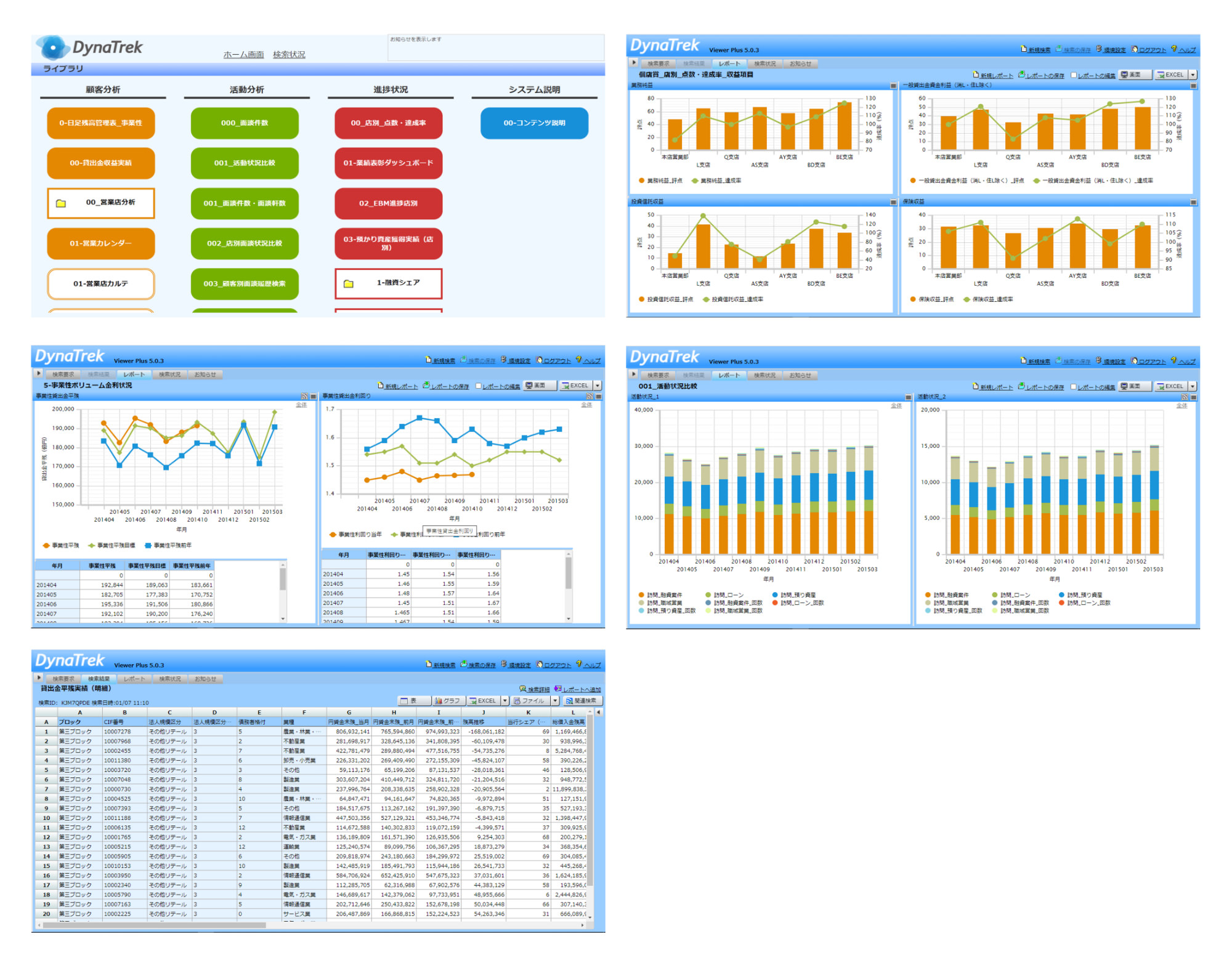
ユーザー層
DYNATREKのユーザー層では、「顧客番号」や「販売収益」、「今期コンタクト回数」など、ユーザーが日常の業務で用いる言葉でデータが定義されています。ユーザーは、DYNATREK Viewerというツールを用いて、この項目を組み合わせて定型帳票を作成したり、グラフを作成するなど、様々なコンテンツを生み出すことができます。
DYNATREK Viewerで作り出したコンテンツは、他のWebシステム画面に貼りだしたり、またDYNATREKの画面をクリックすると別の業務システム画面を表示するなど、「日々の業務に組み込まれる」形のコンテンツも提供することができます。
データ辞書層
DYNATREKのデータ辞書層では、ユーザー層で提供する「顧客番号」や「販売収益」、「今期コンタクト回数」などが、どのシステムのどの項目を参照し、またどのように演算するかを登録することができます。DYNATREKは、データ辞書層に登録されたロジックを、ユーザーの検索毎にダイナミックに各システムへのSQL(データベースへの問い合わせ言語)に変換することで、「あたかもデータベースがそこにある」かのように振る舞うことができます。
多くの企業において、この知識はパワーユーザーの暗黙知となっていることが多く、「ビジネスでつかう用語」と「システムでつかう用語」の橋渡しをおこなうこの部分こそが、DYNATREKで最も重要な役割を果たします。
また、DYNATREKに登録されたデータ辞書は、常にドキュメント化やデータベース化を行うことが可能であり、業務ノウハウの可視化にも大きな役割を果たします。
データ接続層
DYNATREKは、世の中で一般的に活用されるリレーショナルデータベースの殆どの種類と接続することができます。各システムとの接続は「JDBC接続」という汎用的な接続方式をとるため、各システムでのインターフェース開発などは不要です。
また、DYNATREKのデータ接続層では、詳細なログ取得などのセキュリティ機能と、同時接続数や時間の制限といった、「接続先システムに対して影響を与えない」ための機能を数多く備えています。30年来、数多くの大組織のデータベースと接続してきた実績が、データ接続層の「引き出しの多さ」としてご評価いただいております。